
First you have to decide about a fitness function that guides the evolution towards a good solution. The two major approaches I can think of are
- Let the engine search for a best moves in given positions. Engines finding more correct moves are fitter than others.
- Play games among the engines and their scoring determines the winner in a population
The second is closer to the final goal, because at the end you want a strong playing engine and not one that solves a lot of positions, but there seems some correlation between both topics. So an engine that finds the correct move more often is also stronger when playing games. I have yet to find out how strong the correlation is.
When you start thinking about auto tuning with PBIL I suggest you at least start with the 1.st approach (as I did) because of its speed advantages. You can run more evolutions this will help you to get your PBIL framework stable and you can try different settings for the GA to find a suitable set for you (e.g. for Learning Rates, Elitism, Mutation ...).
But before you even start with chess tuning you should solve simpler problems. I used a small matrix problem for that.
A B C
D E F
G H I
where possible values for A - I are 0 - 15. The best solution has the sum of rows and columns all as 24. A working framework should find a perfect solution in no time.
+-----------------------------------------------------------------------+
| Generation: 334 / 500 Population: 100 RunTime: 00:00:01 |
| Worker Threads : 1 Best Fitness: 144 (Age: 131) 0 sec |
+-----------------------------------------------------------------------+
| LR: 0.020/2 NLR: 0.000/1 MP/Drift: 0.000 / 0.050 |
| LR: 0.020/2 NLR: 0.000/1 MP/Drift: 0.000 / 0.050 |
| Elitism: No Entrop: 0.01 |
+-----------------------------------------------------------------------+
| Fitness (-/o/+): 144/144/144 SD: 0 Convergence: 99.990% |
+-----------------------------------------------------------------------+
DNA:
Row1: 10 8 6
Row2: 11 4 9
Row3: 3 12 9
PV Distribution of 36 bits Fitness (mean/max): 144/144
Convergence: 99.99% (0.000%) Entropy: 0.01 (-0.000)
^
| ▄
20 + █
|▄ █
|█ █
|█ █
|█ █
0 +-----+----+----+----+----+----+----+----+----+----+
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Then to the real stuff. When trying to tune an engine with chess positions the selection of "good" positions is very important. Just picking random positions from strong engine games at long time controls is probably not enough. I actually haven't even tried that because I feared that this is a waste of time. The fitness signal might be very weak. A position where the correct move requires a 20 ply search to be found is not very useful. Either no individual in a generation will find it within its search horizon so it does not help to determine the individual fitness or some engines will announce it as best for the wrong reasons.
For similar reasons also positions with tactical solutions (captures, promotions) are less useful because even engines that have the queen value badly wrong will probably go and capture the queen if possible. So almost all engines will solve that, which also does not help to differentiate them.
Therefore I started with positions from games of strong engines but filtered them. I gave them to Stockfish, Houdini and Kommodo and let those engines perform a very shallow search (depth 1or 2). Only if those strong engines were able to find the best move in I considered the position solvable.
- Stockfish is the best (fastest) engine for that
- Houdini 1.5 is a bit slower probably because of some overhead associated with starting a search
- Kommodo is unstable (once in a while it does not come back with a best move after a "go depth 2" and requires an explicit "stop" command to stop searching)
 |
| Probability Convergence of 507 bits towards 0 or 1 |
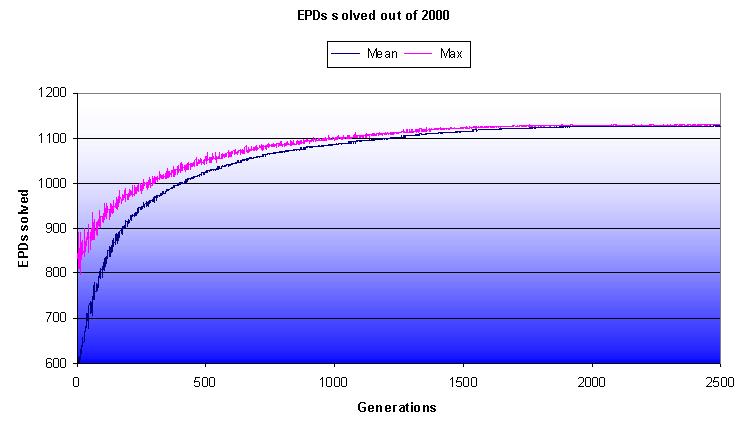 |
| EPDs solved per generation in average and from the best individual (no elitism is used) |
The Training Data:
2000 positions, verified with Houdini 1.5a
http://www.fam-petzke.de/downloads/TD-SUB-2000.epd
The EPD file also contains the score that Houdini awarded for that position, I saved it for maybe further use, but have not used it so far.
looking at your graph it looks like you lowered a lot LR & NLR, I lowered the from the original values int the paper but my convergence is still faster than yours.
ReplyDeleteI calculated convergence as sum(2*abs(probBIT-0.5)) and just after 80 generation it's already 65% are you using the same formula?
I'm trying to optimize 3777 bits, let's see if I could arrange to have a stronger engine at the end of this work:)
btw, thank you for sharing your epd file
In my runs I have set the negative LR to 0 as I feared that in the later generations it will not help very much. The best and worst individuals might not be so far apart. But I used the 2 best individuals to speed the algorithm up a bit. I tried different LRs between 0.02 and 0.05 and also different settings for mutation. The 0.05 converged of course faster but their solutions were a bit worse (in the range of 1% - 2% less positions solved). Looks like I have the same convergence calculation but I don't do anything with it (except displaying). In addition I calculate the entropy within the system (E = -Sum(pv[i] * ln(pv[i])) like a temperature that drops if the system converges. A fully converged system would have an entropy of 0 but I never made it that far. I use the current entropy to adapt the LR. I start with a low one, I increase it as the entropy drops and when the entropy goes under a certain threshold I start lowering it again. This seems to speed up the algorithm without sacrificing quality. BTW I only have 507 bits currently, 3777 bits is a lot. 65% after 80 generations is lightning fast for that.
ReplyDeleteyes it's too fast :)
Deletei slowered it a lot. I use elitarism and the following parameters.
LR 0.01
NLR 0.0075
mutation probability 0.05
mutation shift toward 0.5 =0.05
up to now I'm at the 330 generation, convergence is 56% and it can solve 727 position. My original engine could solve 990 position at depth 1.
I haven't looked at your epd file but I wonder if it could be used to train king safety too. You don't add capture and king attack to the training data point. what do you think about it?
I'm the previous post "unknown",
DeleteHi Marco, the training file I provided includes captures. I haven't filtered them out here. Basically it contains positions from long time control games of strong engines from the side that did win. Positions were the played move was not found already at depth 2 (by a strong engine) were removed. If the position demands a tactics beyond the search horizon that is used in the GA it is not so useful.
DeleteKing safety is an important term in my eval. It was tuned along with anything else, so I guess the training set covers this aspect. But I have tons of test set data. I have written my own little workflow and application just to generate useful test data.
I suspect the elitism leads to fast (and maybe premature) convergence in your case. If in an early generation a strong individual is created the GA will head right into that direction and misses maybe a large part of the solution space. If this elite individual is near a local optimum the GA will not come out of it again as it is already to converged.