As a previous post triggered some interest how I used PBIL to auto tune my evaluation I now publish some more details about my approach.
First you have to decide about a fitness function that guides the evolution towards a good solution. The two major approaches I can think of are
- Let the engine search for a best moves in given positions. Engines finding more correct moves are fitter than others.
- Play games among the engines and their scoring determines the winner in a population
Both have their pros and cons. The 1st one is a bit easier to implement, faster in execution and it is a bit easier to implement multi-threaded.
The second is closer to the final goal, because at the end you want a strong playing engine and not one that solves a lot of positions, but there seems some correlation between both topics. So an engine that finds the correct move more often is also stronger when playing games. I have yet to find out how strong the correlation is.
When you start thinking about auto tuning with PBIL I suggest you at least start with the 1.st approach (as I did) because of its speed advantages. You can run more evolutions this will help you to get your PBIL framework stable and you can try different settings for the GA to find a suitable set for you (e.g. for Learning Rates, Elitism, Mutation ...).
But before you even start with chess tuning you should solve simpler problems. I used a small matrix problem for that.
A B C
D E F
G H I
where possible values for A - I are 0 - 15. The best solution has the sum of rows and columns all as 24. A working framework should find a perfect solution in no time.
+-----------------------------------------------------------------------+
| Generation: 334 / 500 Population: 100 RunTime: 00:00:01 |
| Worker Threads : 1 Best Fitness: 144 (Age: 131) 0 sec |
+-----------------------------------------------------------------------+
| LR: 0.020/2 NLR: 0.000/1 MP/Drift: 0.000 / 0.050 |
| LR: 0.020/2 NLR: 0.000/1 MP/Drift: 0.000 / 0.050 |
| Elitism: No Entrop: 0.01 |
+-----------------------------------------------------------------------+
| Fitness (-/o/+): 144/144/144 SD: 0 Convergence: 99.990% |
+-----------------------------------------------------------------------+
DNA:
Row1: 10 8 6
Row2: 11 4 9
Row3: 3 12 9
PV Distribution of 36 bits Fitness (mean/max): 144/144
Convergence: 99.99% (0.000%) Entropy: 0.01 (-0.000)
^
| ▄
20 + █
|▄ █
|█ █
|█ █
|█ █
0 +-----+----+----+----+----+----+----+----+----+----+
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Then to the real stuff. When trying to tune an engine with chess positions the selection of "good" positions is very important. Just picking random positions from strong engine games at long time controls is probably not enough. I actually haven't even tried that because I feared that this is a waste of time. The fitness signal might be very weak. A position where the correct move requires a 20 ply search to be found is not very useful. Either no individual in a generation will find it within its search horizon so it does not help to determine the individual fitness or some engines will announce it as best for the wrong reasons.
For similar reasons also positions with tactical solutions (captures, promotions) are less useful because even engines that have the queen value badly wrong will probably go and capture the queen if possible. So almost all engines will solve that, which also does not help to differentiate them.
Therefore I started with positions from games of strong engines but filtered them. I gave them to Stockfish, Houdini and Kommodo and let those engines perform a very shallow search (depth 1or 2). Only if those strong engines were able to find the best move in I considered the position solvable.
- Stockfish is the best (fastest) engine for that
- Houdini 1.5 is a bit slower probably because of some overhead associated with starting a search
- Kommodo is unstable (once in a while it does not come back with a best move after a "go depth 2" and requires an explicit "stop" command to stop searching)
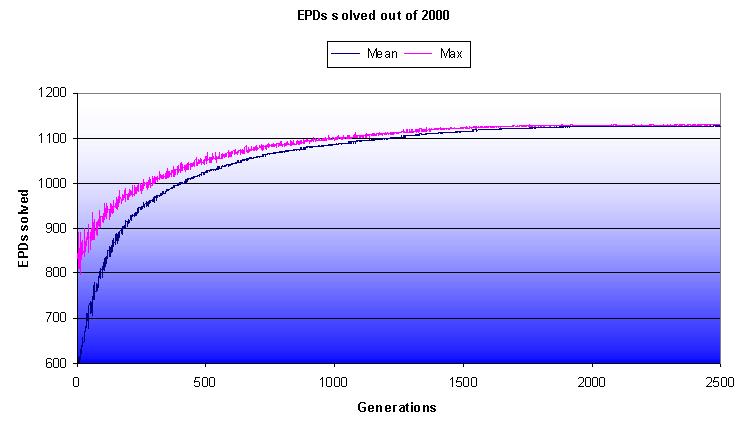
With those positions the algorithm converged very nicely. I here display the performance of an evolution with 2500 generations where I used 2000 filtered EPD positions as training data. I attach a link to the used training data in EPD format below in case someone finds it useful.
 |
| Probability Convergence of 507 bits towards 0 or 1 |
 |
| EPDs solved per generation in average and from the best individual (no elitism is used) |
The Training Data:
2000 positions, verified with Houdini 1.5a
http://www.fam-petzke.de/downloads/TD-SUB-2000.epd
The EPD file also contains the score that Houdini awarded for that position, I saved it for maybe further use, but have not used it so far.